

En este artículo explicamos de forma sencilla conceptos básicos de un modelo de Machine Learning Operation, su implementación y análisis de componentes y arquitectura del ML.
Antes de nada, para poder profundizar en los conceptos de Machine Learning Operation, vamos a tratar de explicar sin profundizar en exceso, qué es el Machine Learning. Seguramente todo el mundo ya haya escuchado acerca de esto, por lo que vamos a intentar describirlo de forma muy sencilla para entender por qué necesitamos Machine Learning Operations (En adelante MLOps) si ya estamos trabajando o si nos estamos planteando trabajar con modelos de aprendizaje automático.
Para intentar definir el concepto de Machine Learning, primero tenemos que entender cuál es el concepto de aprendizaje, ya que todo el proceso de aprendizaje automático está basado e intentar imitar el modelo de aprendizaje que tenemos los humanos.
Aprendizaje se suele definir como “el proceso de adquisición del conocimiento de algo por medio del estudio, el ejercicio o la experiencia”.
El objetivo de los modelos de aprendizaje automático, es llevarnos este concepto a un punto de vista computacional, por lo que trataríamos de definirlo como la adquisición de conocimiento de manera automática mediante la utilización de ejemplos. Estos ejemplos, es lo que los humanos llamamos, experiencias. A estos ejemplos, en adelante, los denominaremos ejemplos de entrenamiento (o set de entrenamiento, conjunto de entrenamiento, etc).
En origen, el modelo de aproximación que se tenía para crear modelos de aprendizaje automático era el de disponer de un conjunto de datos de entrada, que era la información que necesitábamos para tomar una decisión y una serie de reglas, que generalmente eran definidas por un experto de manera estática, y lo que obteníamos era una respuesta, como vemos en la imagen.
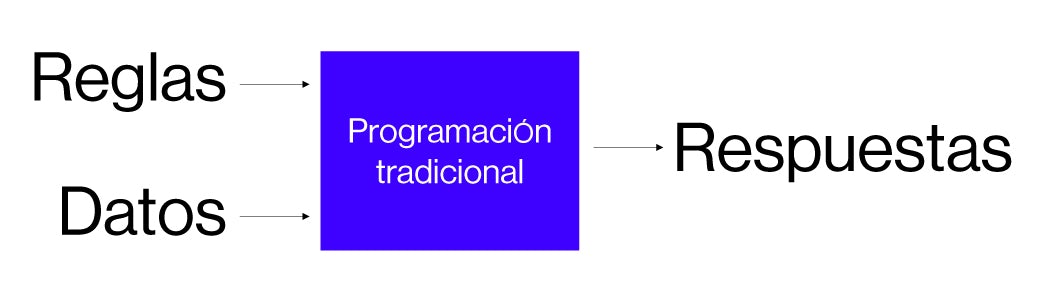
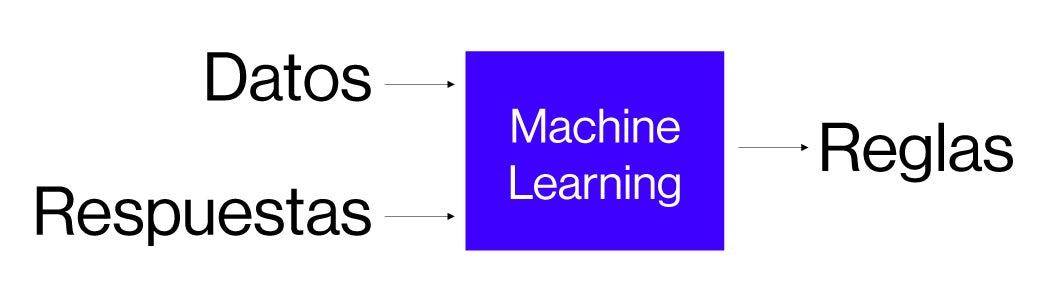
Este tipo de sistemas no eran los mejores para tratar de imitar el proceso del razonamiento humano desde el punto de vista del aprendiz y lo que se hizo fue replantear el método, de manera que, actualmente, se utilizan como entrada las respuestas y los datos. De esta forma, intentamos aprender o imitar el proceso de aprendizaje donde sabemos cuál es el resultado de algo y esto, nos genera, un conjunto de reglas que cuando las empaquetamos, las denominamos modelo de razonamiento o modelo de aprendizaje.
Entendido esto, vamos a plantear el cómo construiríamos un modelo de aprendizaje supervisado. El clásico ejemplo suele ser el de identificar si algo es un animal u otro, una fruta u otra, etc. donde conocemos la variable target a calcular. Supongamos que optamos por las frutas, ¿Cómo construiríamos este modelo?.
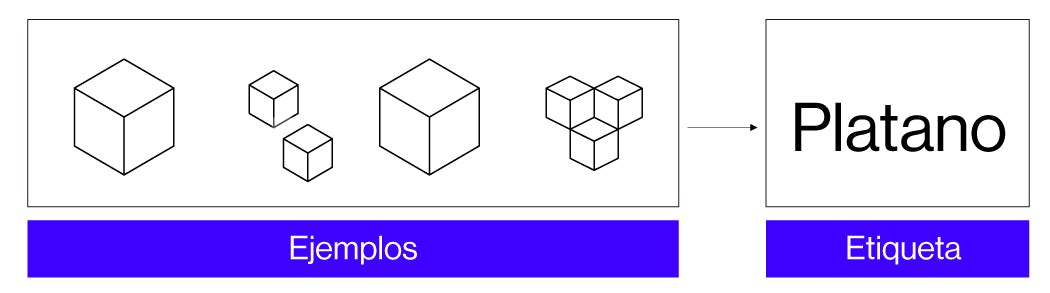
El ciclo de vida de los modelos, está divididos principalmente en dos fases: Fase de entrenamiento y fase de inferencia. La primera, la fase de entrenamiento, generalmente es la más costosa y consiste en utilizar un conjunto de datos como instancias de entrenamiento. Una instancia de entrenamiento es una estructura básica de información donde están cada uno de los atributos que definen en este caso si es una manzana o un plátano (para nuestro ejemplo, podrían ser píxeles) además de un valor especial, fundamental para este tipo de entrenamientos que es el valor que nosotros queremos predecir o utilizar para clasificar, lo que denominamos clase o etiqueta (Si es plátano o manzana).

Generalmente, la etiqueta, es el valor que queremos predecir, clasificar o generar en nuestro sistema de predicción. Por lo tanto, estas instancias de entrenamiento son fundamentales para conseguir realizar esta tarea. Para ello, tenemos que entender cómo está construida o cómo queremos construir estas instancias de entrenamiento ya que habrá que realizar una serie de operaciones previas como pueden ser transformaciones o una selección de características, por ejemplo para producir ese proceso de aprendizaje. Por lo tanto, el set de instancias de entrenamiento es el que deberá tener mayor cantidad de información ya que es fundamental para poder construir el modelo que nos permita obtener esas reglas que son capaces de generar modelos de Machine Learning.
Si vamos profundizando, necesitaremos un conjunto denominado de validación, que es un pequeño conjunto que se genera a partir del set de entrenamiento y que se utiliza para ir validando el modelo que vamos construyendo en tiempo de entrenamiento. Y por último, tendremos el conjunto de test, este, se utiliza para calcular la calidad final del modelo. Lo ideal es que la información que tengamos en este conjunto sea muy diferente a la de entrenamiento y validación, para comprobar si nuestro modelo es capaz de generalizar.
Una vez disponemos de nuestros conjuntos de datos, podemos elegir cual será nuestro modelo de Machine Learning para poder ejecutar ese proceso de entrenamiento. No vamos a entrar en las particularidades de algoritmos de optimización, o de la manipulación del proceso de entrenamiento mediante hiperparámetros, etc. Ya que este post no es objeto de profundizar en los modelos de ML, pero debemos de ser conscientes de que son operaciones que habrá que realizar si queremos tener éxito con nuestro modelo. Una vez realizadas estas tareas, solo faltaría validar nuestro modelo con nuestro conjunto de test.
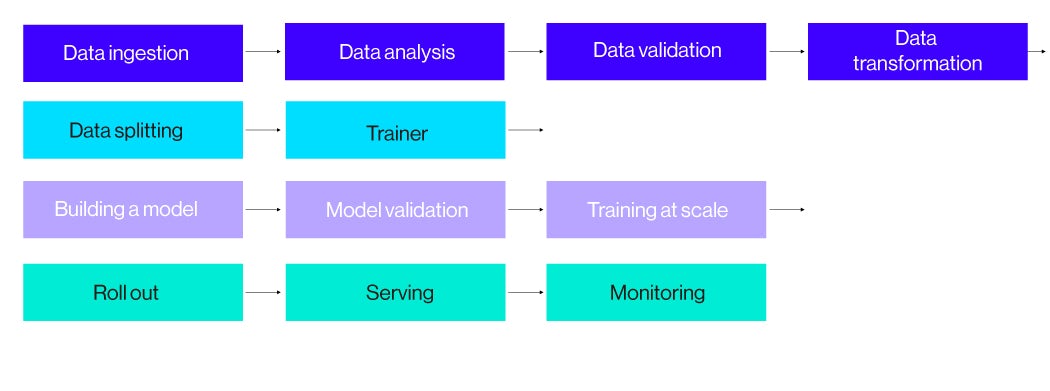
Como veis, y no hemos profundizado demasiado en las particularidades de la creación del modelo, durante la fase de entrenamiento existen un montón de acciones u operaciones que deben ser definidas de alguna manera, dependiendo de lo que queramos hacer con nuestro modelo, estas podrán ser más o menos complejas.
De acuerdo, tenemos el modelo, pero ahora… ¡tenemos que poder desplegarlo y productivizarlo! Además, los algoritmos de aprendizaje automático se construyen mediante un proceso incremental, es decir, todo este proceso de entrenamiento descrito anteriormente, se repite N veces y se construyen diferentes versiones de ese modelo, lo cual hace que tengamos que redesplegar el modelo varias veces aumentando así el número de operaciones. Muchas de las operaciones que hemos comentado son genéricas, como los procesos de selección de características o los procesos de transformación de los datos, entre otras, por lo que nos enfrentamos a un montón de tareas y etapas que deben ser construidas para poder generar nuestro algoritmo.
En un paper de Google, todas estas tareas alrededor del diseño del modelo de ML, Google lo denomina, deuda técnica oculta. Dejamos el enlace al paper para que podáis profundizar en el tema.
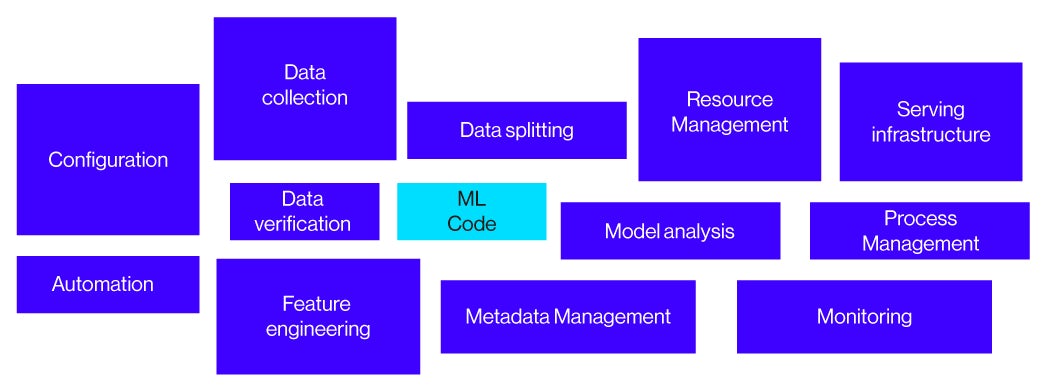
Lo denominan así porque, cuando se comienza con estos temas, nadie espera tener que incluir todos estos elementos para poder utilizar su modelo de Machine Learning desarrollado en un Notebook, pero la realidad siempre es otra.
Antes de continuar vamos a presentar unos datos mostrados en una encuesta del MIT Sloan y BCG de 2019.
- 7/10 empresas reportan poco o nulo impacto con el uso de IA
- El 40% de las organizaciones con inversiones significativas en IA reportan nulos beneficios.
Aunque la realidad es que:
- IA es una fuente de beneficios y oportunidades para las compañías
- Implementar IA es un riesgo.
- Implementar IA correctamente es complicado.
Estos datos en cuanto a lo fructífero que resultan los proyectos de IA, en gran medida es por lo que se denomina Deployment Gap, que viene a decir que existe una brecha en el desarrollo de modelos de machine Learning y su implementación en producción. Generalmente, se encuentra un buen caso de uso para la compañía, desarrollamos un modelo de ML increíble que resuelve dicha necesidad de negocio pero que tiende a morir en un Jupyter Notebook ya que la empresa no cuenta con ese personal que cierre la brecha entre el equipo de científicos de datos con el equipo de IT.
Según la encuesta “State of Enterprise ML de DataRobot de 2020 (Algorithmia entonces):
- El 22% de las empresas que usan ML han implementado con éxito un modelo de ML en producción.
- El 87% de los proyectos de ciencia de datos nunca llegan a producción.
Estos datos son brutales y lo cierto es que, si queremos crear un proceso que tenga un ciclo de vida real, es decir, construir un sistema que sea capaz de construir el modelo, extraer la información correcta, introducir nuevos datos para construir una nueva versión, compararla con los modelos anteriores y desplegar aquel modelo que obtenga unos mejores resultados, la consecuencia es, que tenemos que incluir muchos de estos elementos de la denominada deuda técnica, para gestionarlo todo, desde estructurar correctamente la información hasta controlar su gobierno y monitorización si queremos no formar parte de esas cifras tan pesimistas. Todo esto, sin crear una canalización de datos adecuada, se plantea muy muy complicado.
Para poder gestionarlo, se tiene que, de alguna manera, poder automatizar total o parcialmente todas estas tareas y para ello, se creó el concepto de MLOps. Este, a su vez, deriva del concepto de DevOps o DataOps, este último también bastante tendencia actualmente desde el punto de vista de la gestión de los datos.
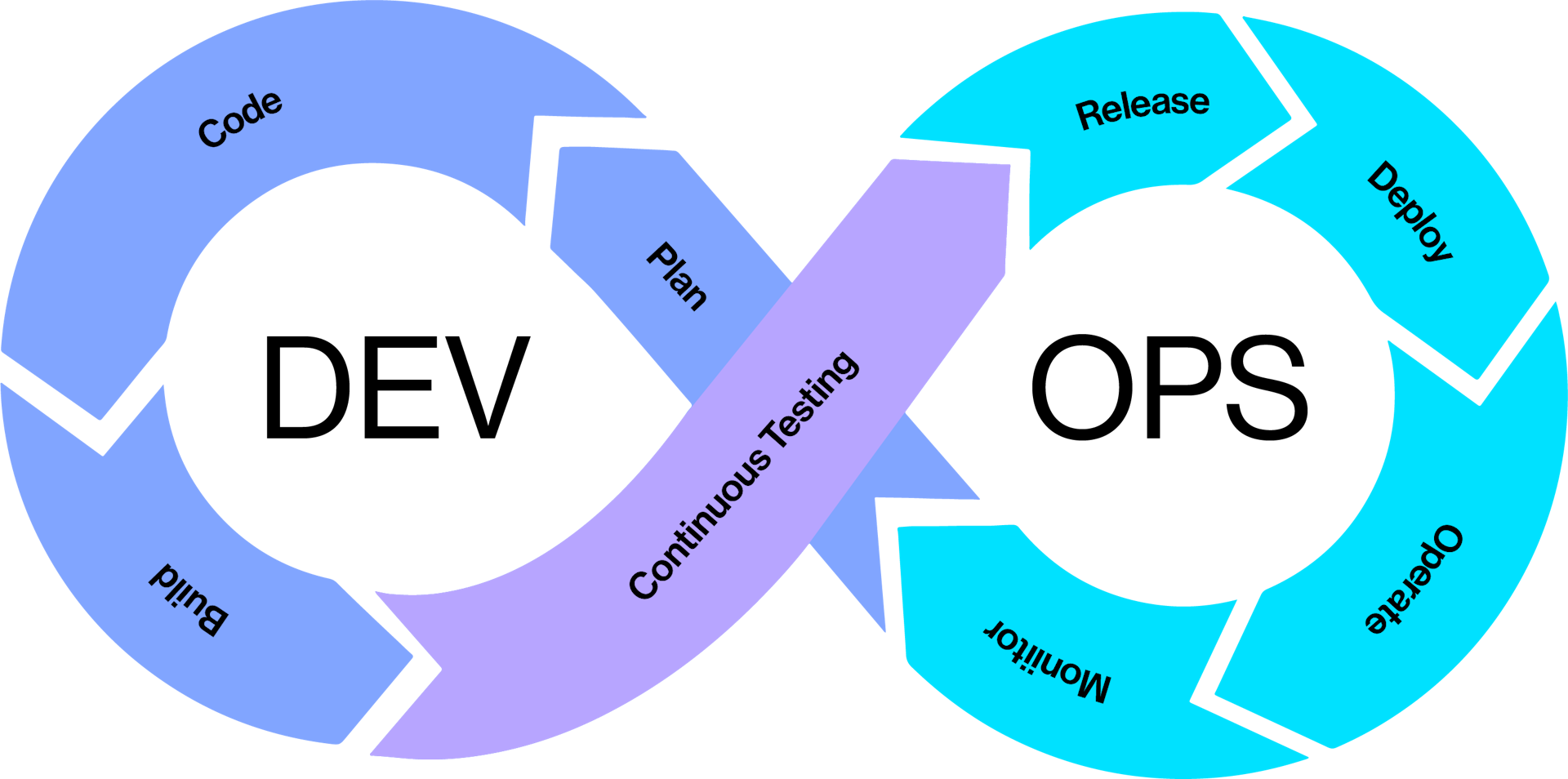
Podemos decir, que crear un modelo de ML se parece mucho a construir software, por ello, se pretendió extender los conceptos de DevOps al proceso de construcción de un modelo. Pero los investigadores, se dieron cuenta de que con esto no era suficiente, había ciertas tareas que no eran capaces de definir, principalmente toda la parte de preparación, análisis y tratamiento de datos así como la aparición de una serie nueva de acciones desde un punto de vista de los modelos de aprendizaje automático, como son la acción del entrenamiento, evaluación del modelo, empaquetado, despliegue y supervisión del modelo, así como la gobernanza de generación del empaquetado de cada una de estas fases.
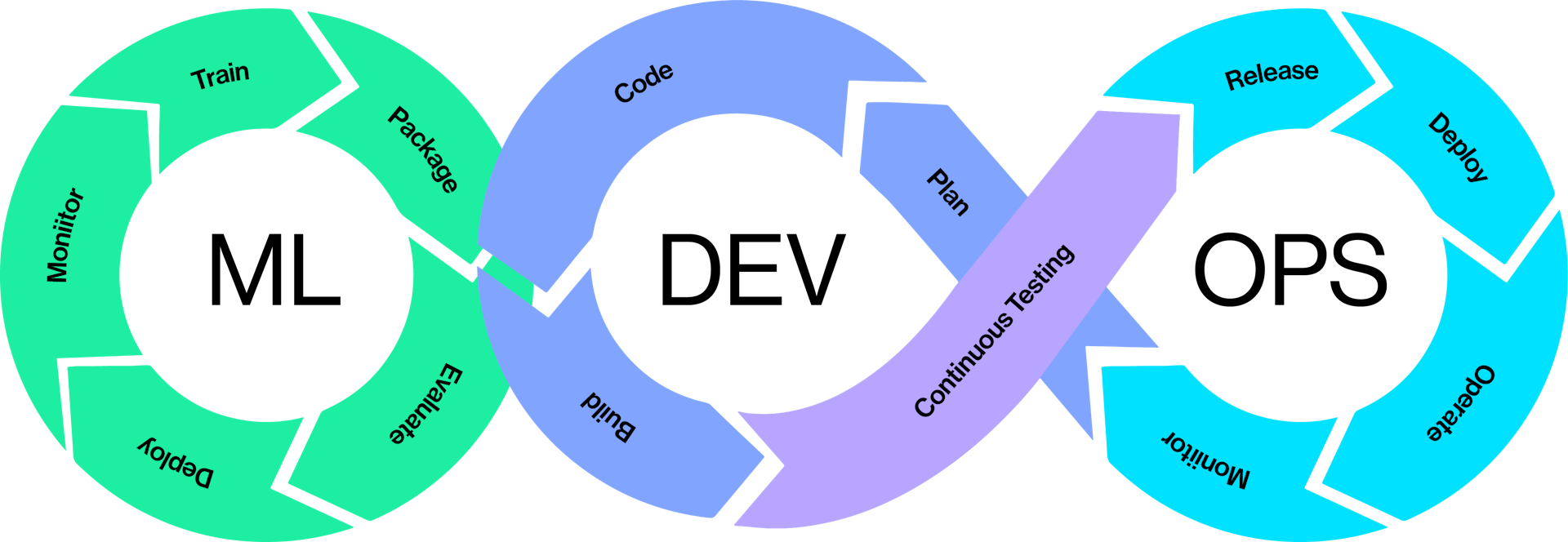
Por lo tanto, el MLOps incluye cinco granes acciones nuevas, las cuales son: Evaluación, despliegue, monitorización, entrenamiento y el empaquetado y para asó completar el ciclo DevOps.
El objetivo de estas 5 fases podríamos describirlo de la siguiente manera:

El entrenamiento: el proceso de entrenamiento hay que tratar que siempre deba ser reproducible, en la medida de las posibilidades, teniendo en cuenta que los datos van a cambiar, el proceso debería ejecutarse exactamente igual para que no haya ningún tipo de variación a la hora de la construcción de los modelos.

Una vez que hemos conseguido construir un modelo de razonamiento, lo siguiente que deberíamos hacer es empaquetar el modelo para facilitar su despliegue mediante el proceso de inferencia. Este paquete, debe contener todo el software necesario para la ejecución. El objetivo es que cuando realizamos este empaquetado, el modelo se pueda ejecutar de manera totalmente aislada, sin necesidad de instalar ningún tipo de software para poder realizar el proceso de inferencia.

A continuación viene la fase de evaluación, en este momento, hay que realizar una evaluación del paquete, es decir, comprobar que este paquete funciona correctamente y que se puede desplegar con garantías en los entornos operacionales donde se va a ejecutar.

Si esta evaluación es satisfactoria, el siguiente paso es realizar el despliegue, este, se tiene que realizar en un entorno de ejecución válido evaluado previamente y que actualmente se suele realizar en infraestructura cloud, donde herramientas como Vertex por parte de Google, Sagemaker, en AWS y MLFlow Azure ML, entre otros, son algunas de las soluciones disponibles para tal uso.

Todos estos procesos como la inferencia, deberán estar monitorizados, tenemos que ser capaces de obtener información de cada una de las etapas para entender que es lo que está sucediendo en nuestro sistema.
Una vez que tenemos control y podemos desplegar las 5 etapas, podemos cerrar el ciclo con el reentrenamiento de nuestro modelo, con el objetivo de mejorarlo en base a la información que recogemos de los usuarios del modelo o al incremento o modificación de la información de entrenamiento.
Como os podéis imaginar, un proyecto de ML no es una caja negra donde tengamos que disponer de todas estas fases u etapas de forma automatizada, existen distintos niveles de automatización que podemos aplicar a nuestro sistema de construcción y despliegue de modelos.
Existen diferentes niveles de madurez, los cuales dependen del grado de automatización de las operaciones del proceso de MLOps.
Para entender nuestro grado de automatización, podemos verificar si se cumple alguna de estas tres:
- La integración continua: Ya no consiste únicamente en comprobar y validar el código fuente y los componentes si no también el comprobar y validar los datos, los esquemas y los modelos.
- La entrega continua: Ya no consiste en la entrega de un único paquete software o servicio, si no de entregar una canalización completa de un proceso de ML.
- Entrenamiento continuo: El modelo de razonamiento que estamos entregando se tiene que entrenar de manera incremental y se tiene que entregar una vez finalizado dicho entrenamiento siempre y cuando se mejore algunas de las características marcadas para realizar una sustitución del modelo que actualmente tenemos desplegado en producción. Esta es probablemente la fase más importante dentro del proceso de automatización.
En base a estas tres reglas (simplificado, el proceso siempre suele ser más complejo), podemos entender cuál es nuestro nivel de automatización.
Por poner un ejemplo, generalmente, las empresas que llevan un tiempo trabajando con algoritmos de ML, suelen automatizar toda la fase de preparación del dato, la parte de entrenamiento, evaluación y validación del modelo, puede estar o no automatizada, pero el despliegue de modelos, y el proceso de servir el modelo, se suele realizar de forma manual. Por ejemplo, los científicos de datos compilan el modelo, es decir, lo entrenan, lo preparan y se lo dan a los ingenieros como un artefacto y estos, lo despliegan de manera manual generalmente ejecutando algún script desarrollado para tal uso.
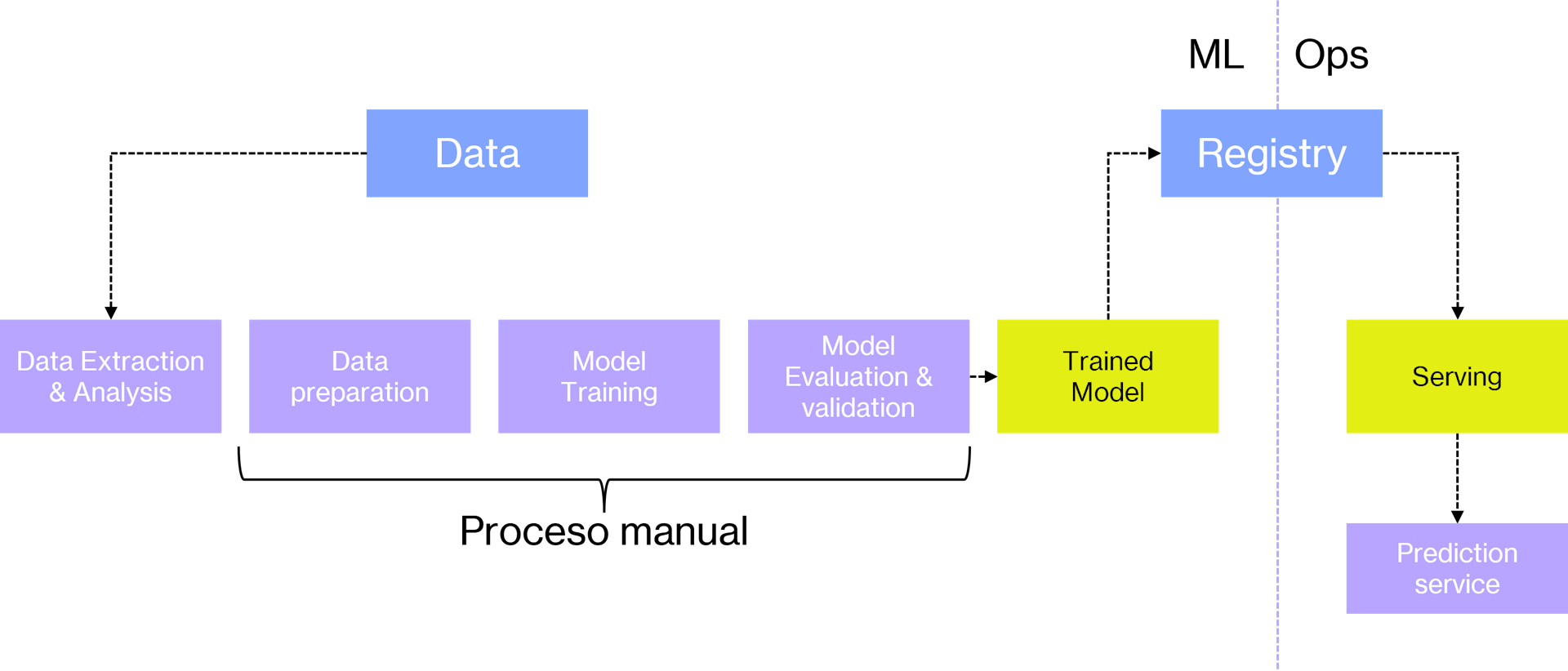
Hasta aquí, tenemos un proceso prácticamente manual. No tenemos integración continua, ni entrega continua, el modelo, hasta cierto punto se genera también de forma manual y no existe monitorización, quizás la única monitorización que existe es la que hacen aquellas personas que ejecuten este código o que programan su ejecución.
Como podemos ver, hay aún mucho trabajo para llevar este modelo de trabajo, que puede ser generalista a muchos clientes, hasta un modelo de automatización completo.
Entendiendo este ejemplo anterior como nuestro punto de partida, el siguiente paso debería ser tratar de automatizar de manera total el proceso de aprendizaje. Es decir, tratar de conseguir una conexión directa automatizada entre los procesos de aprendizaje automático y las operaciones. Por lo tanto obtendríamos que toda la generación del modelo fuera automática y reproducible, sin necesidad de realizar ninguna tarea manual, donde los ingenieros de ML y los científicos de datos, pudieran desplegar de manera automática los modelos sin intervención directa de los ingenieros, es decir, que se pueda desplegar de forma completa el pipe de entrenamiento y despliegue de forma totalmente automatizada.
Adicionalmente, se deberá contar con un versionado de modelos (y un registro de modelos) automático y la posibilidad de reutilizar componentes en la parte de aprendizaje. Solo faltaría mencionar el disponer de un sistema de monitorización que esté pendiente de todos estos procesos. En este punto si dispondríamos de entrega continua, pero aun nos faltaría la parte de integración continua.
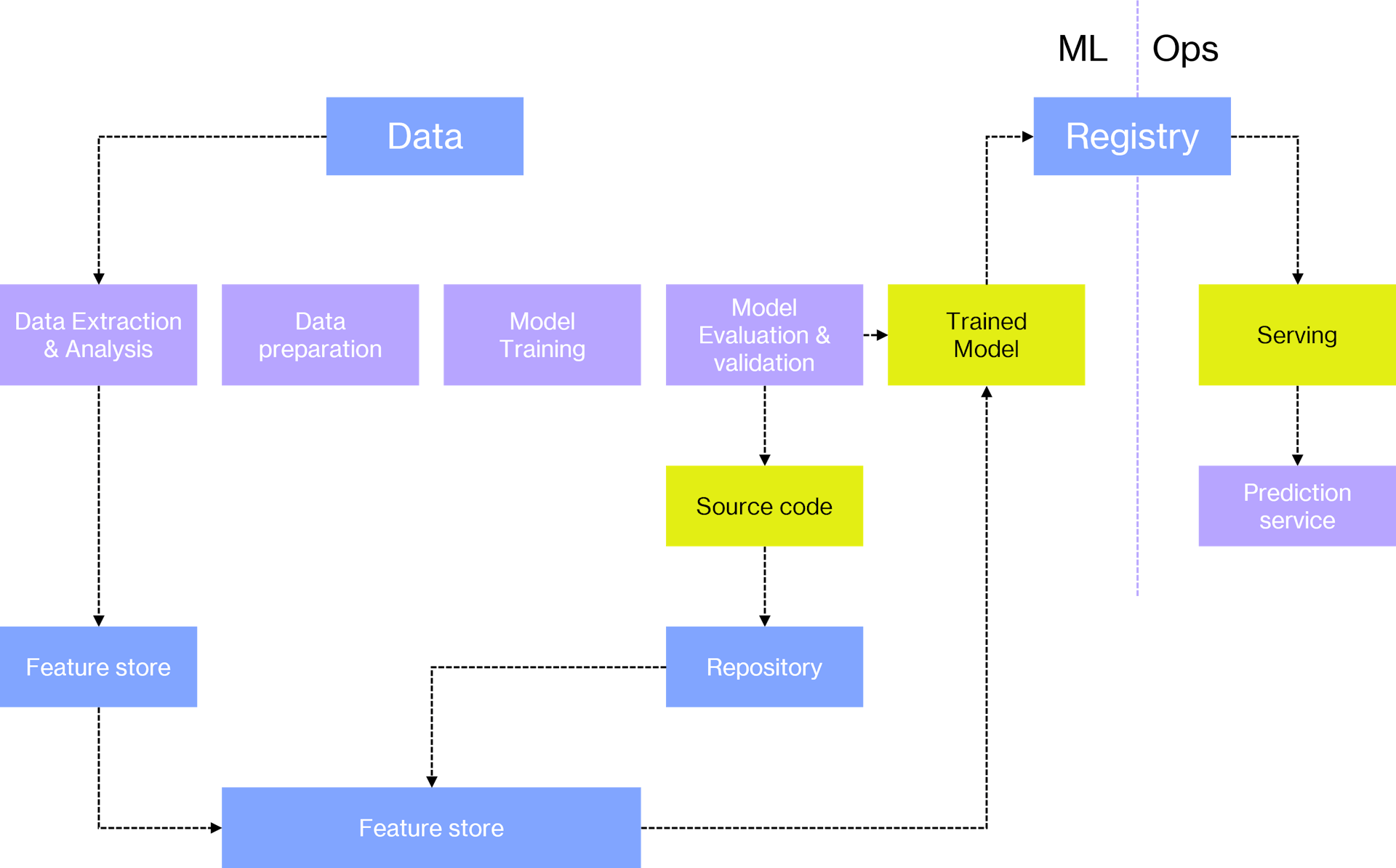
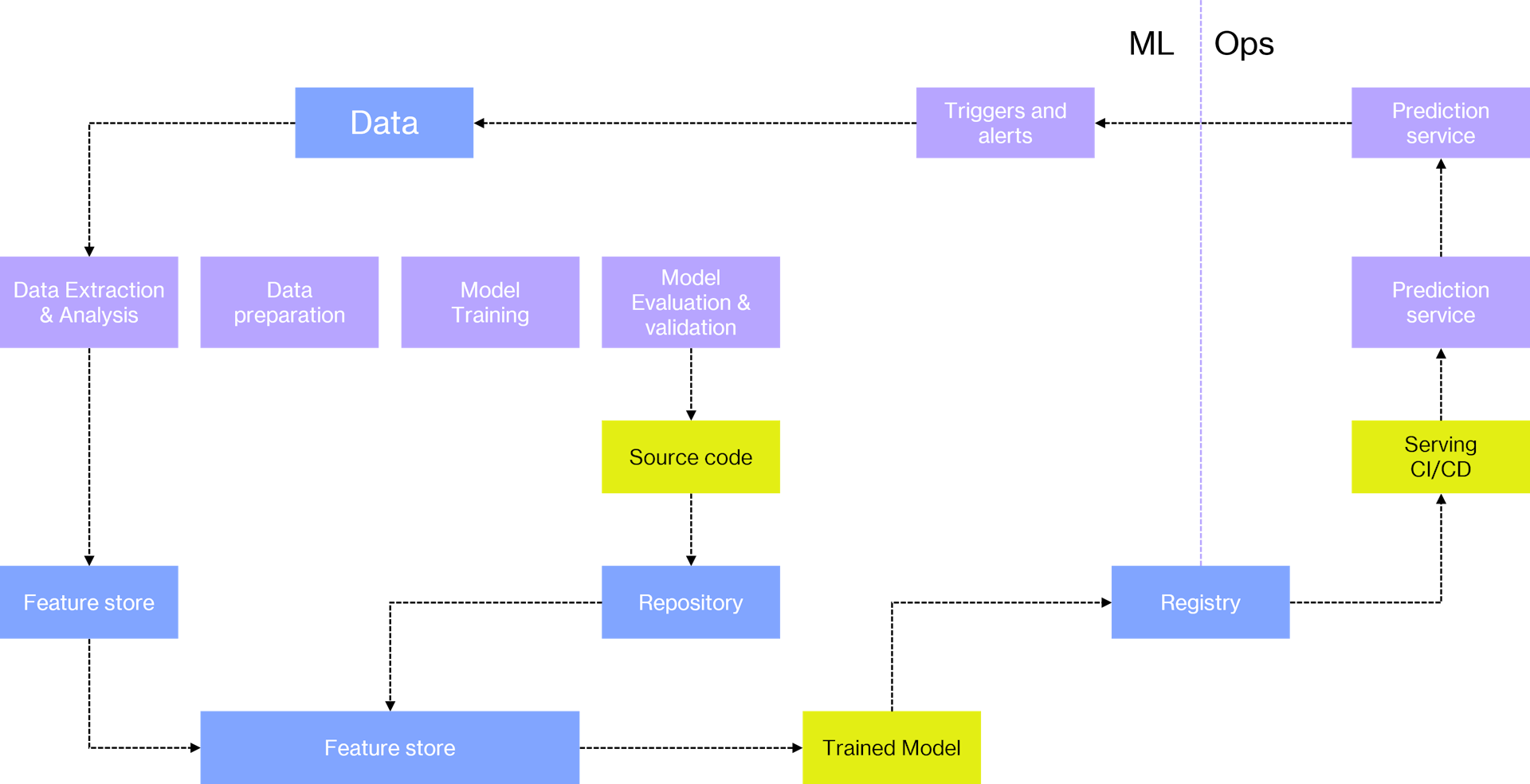
Si hemos sido capaces de llevar nuestra arquitectura de ML a este nivel, ya estaríamos cerca de tan ansiado máximo nivel de automatización, donde automatizaríamos el proceso de integración continua también.
Lo que tendríamos sería todo absolutamente automatizado, desde la orquestación del código, su despliegue, su experimentación, su ejecución, etc. El código fuente estaría controlado y su despliegue automatizado, los servicios de compilación y testing de código también incluidos en el proceso. Habría integración y entrega continua, versionado automático de modelos, monitorización completa del proceso, gestión de los metadatos de todo el proceso de aprendizaje automático, con todas las canalizaciones automatizadas y almacenadas como código fuente que puede ser desplegado de forma automática… El objetivo final sería que los científicos de datos puedan modificar el código de cualquier fase del proceso de aprendizaje y el sistema, automáticamente pudiera desplegar la nueva versión teniendo todos los elementos de la famosa deuda técnica en cuenta.
Como hemos visto, el concepto de MLOps ha llegado para quedarse si queremos tener éxito a la hora de implementar IA dentro de nuestras compañías, el camino no es sencillo, por lo que si no se cuenta con el personal o la experiencia necesaria, es muy fácil que acabemos en ese 87% de empresas que nunca ponen sus modelos en producción. Desde SoftwareOne podemos ayudar a conseguir los objetivos marcados dentro de este tipo de proyectos, por lo que no duden en ponerse en contacto con nosotros si lo necesitan.
Author


